

前回に引き続きスクレイピングしてみたいと思います。
スクレイピングで使われるパッケージとして、【BeautifulSoup】があります。
今回はこのパッケージを使ってスクレイピングで遊びたいと思います。
ちなみに「ビューティフルスープ」と読みますw
BeautifulSoupってどんなパッケージなのか?
HTML や XML から特定のデータを抽出するためのライブラリです。
HTMLやXMLのデータがあれば、そのデータを解析してくれるという優れものです!
ただ逆に言うとデータがなければ何もできません。
データ解析に特化したパッケージですね!
[BeautifulSoup]と[Selenium]どこが違うのか?
HTMLを解析できる点では、同じです。
ただSeleniumはウェブサイトにアクセスができるので、1つのパッケージで完結できます。
その為、[BeautifulSoup]では、[urllib(正確にはurllib内のrequest)]と組み合わせて使うことが多いと思われます。

表にすると上記みたいな感じですね。
その為、[Selenium+BeautifulSoup]や[urllib+BeautifulSoup]の組み合わせで使用は可能です。
今回は[Selenium+BeautifuSoup]の組み合わせで行いたいと思います。
事前準備
BeautifulSoupをインストールする
まずは、[BeautifulSoup]をインストールしていきましょう。
下記コマンドを実行してください。
pip install beautifulsoup4
補足)ビューティフルスープ3もあるらしいですが、サポートが終了しており、4を使いましょう!
Seleniumをインストール
次は、ウェブにアクセスするためのパッケージとして[Selenium]をインストールします。
pip install selenium
実際にコードを書いてみる
やる事(簡易仕様)
前回と同様に、「TSUTAYA 土佐道路店 の在庫確認」をやってみたいと思います。
最近読みたい本があるんです。
それは【HSPサラリーマン 人に疲れやすい僕が、楽しく働けるようになったワケ】という本です。

リンク:HSPサラリーマン 人に疲れやすい僕が、楽しく働けるようになったワケ/春明力 セル本 – TSUTAYA 店舗情報 – レンタル・販売 在庫検索 (tsite.jp)
【在庫結果】をポップアップで表示する仕様にしたい。
URL(ウェブページ)にアクセスする
ここは前回と同様なので画像だけで行います。
これでウェブページにアクセスできました。
現在のHTMLを取得する
現在アクセスしているページのHTMLを取得したいと思います。

driver.page_source
一部ですが、printの結果は下記のようになりました。
データはちゃんと取れていそうです。

BeautifulSoupを使って、データを取得
今回は括りを指定しながら目的のデータへたどり着きたいと思います。
[F12]を押して、開発ツールで確認していきました。
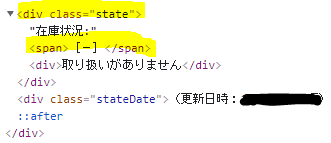
欲しい情報は、在庫情報で、[class=”state”]の中にある[span]のデータにありました。

from bs4 import BeautifulSoup
soup = BeautifulSoup(htmldata, 'html.parser')
element = soup.find(class_='state').find('span')
print(element.text)
流れとしては、先ほど取得したhtmlデータをBeautifulSoupにいれます。
そして、htmlの構造を指定しながら取得していきます。
エラーになった人へ
beautifulsoupでエレメントが見つからず、エラーになる時があります。
何度確認しても構造の指定もあっているになぜ。。。とはまってしまします。
自分もでました。

これは、beutifulsoupでエレメントの取得の失敗のですが、ウェブサイトによって少し待たないと正確にhtmlが完成していないことがあります。
ウェブサイトの作りでJavaScriptが動いていると発生することがあるそうです。
このようなエラーになった人は、ウェブページをアクセス後、少しウェイトを置いて取得するようにしましょう。
完成したコードはこちら
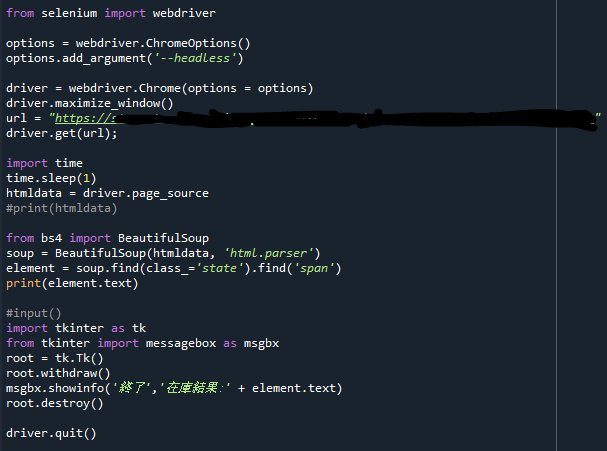
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options = options)
driver.maximize_window()
url = "https://(アクセスしたいURL)"
driver.get(url);
import time
time.sleep(1)
htmldata = driver.page_source
#print(htmldata)
from bs4 import BeautifulSoup
soup = BeautifulSoup(htmldata, 'html.parser')
element = soup.find(class_='state').find('span')
print(element.text)
#input()
import tkinter as tk
from tkinter import messagebox as msgbx
root = tk.Tk()
root.withdraw()
msgbx.showinfo('終了','在庫結果:' + element.text)
root.destroy()
driver.quit()
ウィンドウは非表示で実行するようにしています。そっちの方が裏で動いてる感がでるのでw
もし、動いている所が見たい人は、[ options.add_argument(‘–headless’) ]をコメントにしてください。
まとめ
今回は、BeautifulSoupを使って、ウェブサイトの欲しいデータを取得することをしました。
ウェブサイトまでのアクセスは[Selenium]を使いましたが、[urllib]を使っても問題ありません。
[urllib]との組み合わせの方が情報にあふれていますw
自分的にはSelenium使えるなら、BeautifulSoupを使う必要はないかなと考えています。
ただし、今回のサイトのようにウェイトを置かないとデータが取得できない場合は、[urllib]の方が確実に取得できると思っています。※経験上です
使ってみて、メリットとデメリットを体感して、選択できるようになる方がいいと考えているので、ぜひとも[urllib]でもやってみてはいかがでしょうか?

業務でプログラミング(C#/VB/Python)を作っている。
挫折を何回も繰り返し、幾度の壁を乗り越えてきた。
乗り越えてきた事を忘れないように記録に残す。
同じ思いをしている人への情報提供になれたらと思う。
基本は初心者に向けたプログラムの情報を提供する。


コメント