

Seleniumを使ったスクレイピングに挑戦したいと思います。
自分はスクレイピングの方法は2種類知っています。
①[Selenium]を使う
②[urllib + beautifulsoup]を使う
前回までSeleniumを使っていたので、引き続きSeleniumを使っていきたいと思います。
スクレイピングとは。。。
Webページから特定の情報だけ抽出する技術のことです。
ただスクレイピングをするにあたっては、そのウェブページを運営している企業がAPIを提供しているかを調べてください。
大手企業が運営しているウェブページではAPIが無料で配布されている場合があります。
APIを優先的に使う理由としては、ウェブページの負荷を減らす事になるので、優先的にしていただければと思います。
APIとは、今回の場合、自分とウェブサイト間をつなぐ架け橋です。
正確には、下記の説明。
アプリケーションプログラミングインタフェース(API、英: Application Programming Interface)とは、広義ではソフトウェアコンポーネント同士が互いに情報をやりとりするのに使用するインターフェースの仕様である。
アプリケーションプログラミングインタフェース – Wikipedia
スクレイピングをしてみた
TSUTAYAの在庫をチェックする。
今回は、「TSUTAYAの在庫確認」をやってみたいと思います。
実は、最近読みたい本があるんです。
それは【HSPサラリーマン 人に疲れやすい僕が、楽しく働けるようになったワケ】という本です。

リンク:HSPサラリーマン 人に疲れやすい僕が、楽しく働けるようになったワケ/春明力 セル本 – TSUTAYA 店舗情報 – レンタル・販売 在庫検索 (tsite.jp)
今回はお試しとして、【TSUTAYA 土佐道路店】にあるか調べてみます。
では、URLを調べてみます。
※今日から毎日チェックし、【在庫有】になったら、ポップアップが上がる仕様にしたい。
URLの法則を見つけると、今後の自動化につながるので、法則を見つけておきましょう。
例えば、今回のURLは、ISBN-13(JANコード)とStoreIDがわかると色々とできそうです。
在庫情報を取得する
まずはエレメントを調べる必要がありますので、ブラウザ開発ツール(F12)で調べましょう。
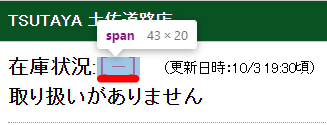
ここのXPathを取得します。
取得したら、そのTextを取得し、表示させます。
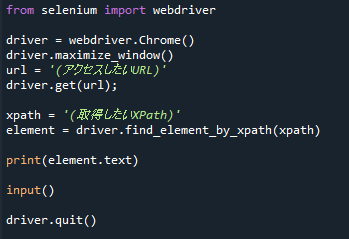
from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() url = (アクセスしたいURL) driver.get(url); xpath = (取得したXPath) element = driver.find_element_by_xpath(xpath) print(element.text) input() driver.quit()

XPathから取得したエレメントのテキストをプリントで表示しています。
element.text
結果も問題なく表示できています。
後は、在庫結果を表示するようにするようにしたいと思います。
在庫結果の表示
ここは、スクレイピングは関係ありませんw
ちょっと自分好みにするための処理です。
自分のコードで【input()】の部分を、在庫の結果を表示するメッセージボックスを表示させたいと思います。
メッセージボックスを出すために、【tkinter】というパッケージを使います。
このパッケージはGUI(Graphic User Interface)というウィンドウを作るパッケージです。
このパッケージをインストールしていない場合は、インストールお願いします。
①【tkinter】のインスタンスをつくる
②魔法の1行をかく
③メッセージボックス表示
④【tkinter】を開放する
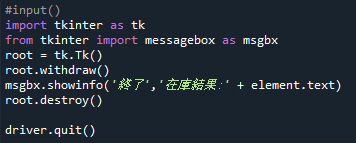
import tkinter as tk
from tkinter import messagebox as msgbx
root = tk.Tk()
root.withdraw()
msgbx.showinfo('終了','在庫結果:' + element.text)
root.destroy()

在庫結果を表示できるようになりました。OKを押すと、ウィンドウを閉じます。
動作的に大丈夫そうであれば、ウィンドウは非表示で動作すると、裏で動いてる感がでますw
コードの紹介(画像のみ)
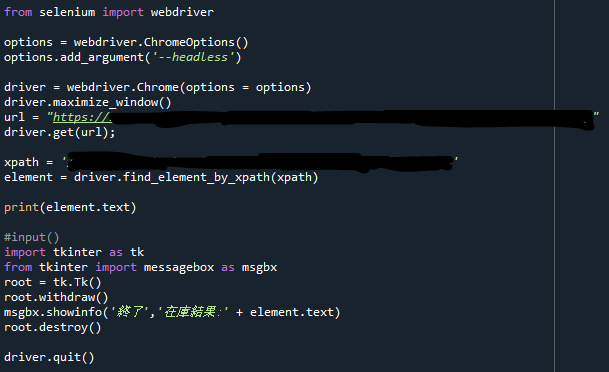
毎日決まった時間に起動するようにする
このPythonプログラムができたら、Windowsのスケジューラーを使って、毎日決まった時間に起動するように設定しましょう。
使い方については、今回、省略します。

まとめ
今回、Seleniumを使って、TSUTAYAの在庫のスクレイピングに挑戦しました。
日々1回アクセスするだけなので、サーバーの負荷にはならないと思いますので大丈夫と考えています。
ただ、これを応用して、連続でアクセスするような事を考えている人は、注意してください。
気が向いたら、[urllib+beautifulsoup]を利用したスクレイピングを紹介できればと思います。

業務でプログラミング(C#/VB/Python)を作っている。
挫折を何回も繰り返し、幾度の壁を乗り越えてきた。
乗り越えてきた事を忘れないように記録に残す。
同じ思いをしている人への情報提供になれたらと思う。
基本は初心者に向けたプログラムの情報を提供する。


コメント